- Sigmoid
- Posts
- Când explodează Soarele, AI va fi primul care va afla
Când explodează Soarele, AI va fi primul care va afla
Prognoza meteo? Acum și în spațiu
Sigmoid AI
September 01, 2025

hello dragi sigmariteni, happy Autumn
iată care sunt highlight-urile lunii august: modele care pot prezice vremea din spațiu, care editează imagini, sau care le transformă în modele 3D, care generează lumi interactive, sau sunt specializate în descoperirea de proteine și ingineria celulară, un AI ce cartografiază schimbările planetei, și multe altele.
fă-ți cafeluța, bucură-te de ultimele zile de căldură și începe luna alături de Sigmoid!
Când explodează Soarele, AI va fi primul care va afla

NASA, împreună cu IBM, au lansat Surya Heliophysics Foundation Model, un model ce îi va ajuta pe oamenii de știință să prezică vremea din spațiu, precum erupțiile solare. Surya a fost antrenat pe 9 ani de date de la Solar Dynamics Observatory, iar arhitectura sa este una avansată, bazată pe un transformer vizual cu rază lungă și scurtă, însoțit de spectral gating.
În testări preliminare, Surya a dublat timpul de avertizare pentru erupțiile solare, oferind operatorilor de sateliți până la două ore înainte de apariția acestora - dublu față de strategiile clasice - și a îmbunătățit acuratețea clasificării erupțiilor cu aproximativ 16 %. În plus, modelul este open-source și disponibil pe platforme precum Hugging Face și GitHub, încurajând colaborarea globală pentru o mai bună protecție a infrastructurii dependente de tehnologie.
Acum poți experimenta gold-medal AI reasoning

Google lansează Gemini 2.5 Deep Think, primul său model public multi-agent cu „gândire paralelă”. Acest mod avansat de raționament, disponibil în aplicația Gemini pentru abonații AI Ultra, utilizează simultan mai multe agenți AI care explorează idei diverse, revizuiește și combină cele mai promițătoare înainte de a oferi un răspuns final. Spre deosebire de limitările modelelor tradiționale care procesează idei într-un lanț linear, Deep Think adoptă un „thinking time” extins și modalități de gândire în paralel, oferind soluții mai nuanțate și creative.
Capabilitățile sale impresionante sunt demonstrate prin benchmark‑uri precum Humanity’s Last Exam, LiveCodeBench V6 și chiar un rezultat de grad Bronze la Olimpiada Internațională de Matematică 2025, confirmând nivelul său competitiv în sarcini complexe de matematică, programare și raționament creativ.
Deep Think: mai puțini tokeni, mai multă inteligență
Meta a lansat Deep Think, o nouă metodă de gândire a modelelor AI, cu performanță mai bună și eficiență ridicată. Tehnica, denumită oficial DeepConf (Deep Think with Confidence), folosește semnale interne de încredere pentru a elimina traseele de raționament mai slabe și a păstra doar cele relevante. Astfel, modelele pot obține rezultate corecte cu până la 85 % mai puțini tokeni generați, ceea ce înseamnă timp mai scurt și costuri reduse. În testele recente, DeepConf a atins o acuratețe de 99,9% pe AIME 2025, un rezultat record pentru modele open-source, și poate fi aplicată fără antrenare suplimentară pe sisteme precum GPT-OSS sau Qwen3.
Vino la Dreamiconx - The Startup Sales Playbook
Pe 10 septembrie, la Dreamiconx - The Startup Sales Playbook, Urban Business Center Chișinău, se adună cei mai buni oameni din vânzări, fondatori și lideri de startup pentru o zi dedicată creșterii și scalării internaționale. Printre speakeri îi vei întâlni pe:
Speakerii nu vin doar cu teorie, ci cu experiență practică, fundamentală, – cum au reușit să vândă, să scaleze și să deschidă noi piețe, inclusiv la nivel internațional. Vino la conferință și accesează:
Playbook complet: Sesiuni pe Lead Generation → Closing → Customer Retention
Speakeri cu experiență internațională în vânzări, growth și scalare
Studii de caz reale din startup-uri locale care au reușit
Workshopuri practice, hands-on
Know-how global, inspirație și recomandări pentru ecosistemul local
Networking autentic cu fondatori, experți, potențiali clienți, parteneri, angajați
Rezervă-ți biletul aici - https://bit.ly/dreamiconxtickets. De asemena, poți beneficia de 25% reducere folosind promocode-ul DREAMFRIENDS pe Eventino sau Unde .
Dacă vrei să crești mai repede, să vinzi mai bine și să treci la nivelul următor cu startup-ul sau cariera ta, Dreamiconx este locul unde trebuie să fii.
Vrei să câștigi un milion de dolari?
Bill Gates a lansat o competiție prin care oferă 1 milion de dolari pentru dezvoltarea unei soluții cu ajutorul AI pentru a trata boala Alzheimer. Această inițiativă se numește Alzheimer’s Insights AI Prize și scopul competiției este de a stimula crearea unor sisteme AI agentice - capabile să planifice, raționeze și acționeze autonom - care pot analiza cantități masive de date existente pentru a descoperi insight-uri noi în domeniul demenței și Alzheimer. Soluția câștigătoare va fi disponibilă gratuit pe platforma cloud AD Workbench, permițând cercetătorilor din întreaga lume să o utilizeze în colaborări științifice.
Semifinaliștii vor fi selectați pentru a prezenta la conferința CTAD din San Diego în decembrie 2025, iar finaliștii își vor prezenta soluțiile la conferința AD/PD din Copenhaga, în martie 2026.
Cum poți crea selfie-ul perfect cu Gemini?
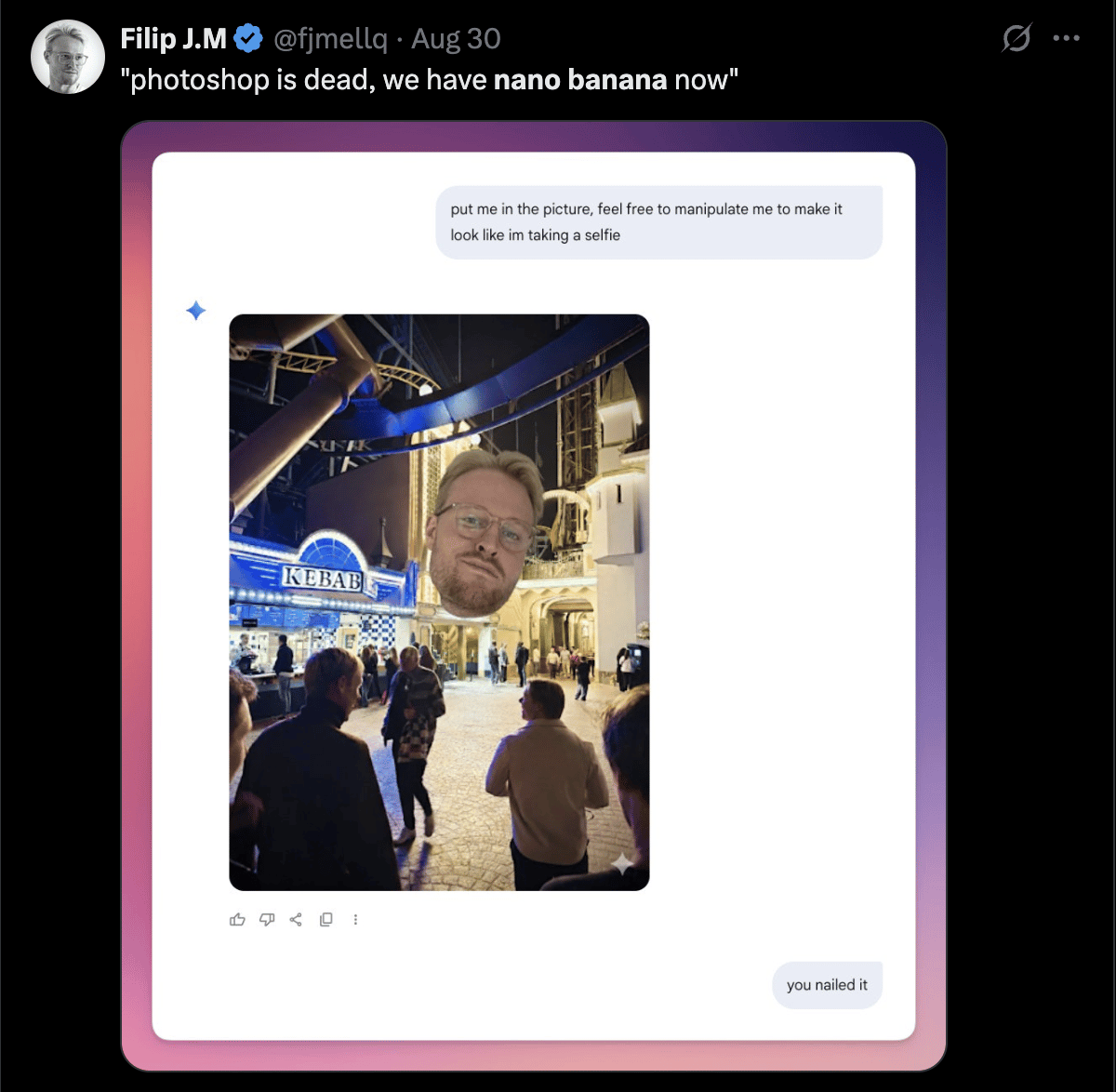
Gemini a integrat un nou model de editare a imaginilor, denumit Nano Banana. Acest upgrade, cunoscut și sub numele Gemini 2.5 Flash Image, este disponibil în aplicația Gemini atât pentru utilizatorii gratuiți, cât și pentru cei Premium. Modelul se remarcă prin capacitatea de a păstra fidel identitatea persoanelor sau animalelor atunci când se aplică schimbări majore, cum ar fi fundaluri noi, transformări de stil sau costume generate de AI.
Nano Banana permite realizarea de editări succesive asupra aceleiași imagini fără a deteriora modificările anterioare și oferă funcții avansate precum fuziunea de stiluri, combinarea mai multor fotografii într-o scenă coerentă, colorarea imaginilor alb-negru, eliminarea elementelor nedorite sau ajustarea fundalurilor. Toate acestea se realizează prin comenzi textuale simple, făcând editarea accesibilă oricui, fără cunoștințe tehnice avansate.
Pentru a garanta transparența, toate imaginile generate sunt marcate atât cu o etichetă vizibilă, cât și cu un watermark digital invizibil SynthID. În esență, Nano Banana transformă editarea foto într-o experiență intuitivă și puternică, aducând funcționalități de tip Photoshop direct în mâna utilizatorilor prin intermediul AI.
Planeta în pixeli

Google DeepMind lansează AlphaEarth, un AI ce cartografiază schimbările planetei ca un „satelit virtual”. AlphaEarth Foundations integrează petabytes de date variate - imagini satelit, radar, simulări climatice, topografie - într-o reprezentare digitală uniformă („embeddings”) accesibilă și ușor analizabilă pentru sisteme automate.
Modelul poate cartografia suprafețe terestre și zone de coastă cu precizie la nivel de 10 metri, oferind imagini detaliate chiar și în zone greu accesibile, precum Antarctica sau terenuri agricole acoperite de nori. În testări, a prezentat o eroare medie cu aproximativ 24% mai mică comparativ cu alte modele similare, confirmând capabilități superioare de monitorizare globală.
Aceste „embeddings” sunt deja disponibile anual, prin intermediul Google Earth Engine, sub forma setului numit Satellite Embedding dataset, folosit de peste 50 de organizații pentru aplicații reale: clasificare de ecosisteme necartate, analiza terenurilor agricole, supravegherea schimbărilor climatice și multe altele.
GPT 5: Nu e încă AGI, but still a beast
ChatGPT 5 este un sistem care include un model eficient pentru sarcinile simple și deeper reasoning model pentru sarcinile mai complicate, gestionate automat de un router intern care decide cea mai potrivită abordare. În plus, noul model vine cu abilități îmbunătățite în scrierea creativă, programare, debugging și științe.
Acum, în mai puțin timp și cu 50-80% mai puțini tokeni, acesta obține rezultate mai bune decât alte modele, precum o3. Acesta are și o rată mai redusă a halucinațiilor, comparativ cu modelele vechi, până la 80 % mai puține erori comparativ cu modelele din seria o3 și aproximativ 45 % mai puține decât GPT‑4o.
Din 2D în 3D în câteva secunde
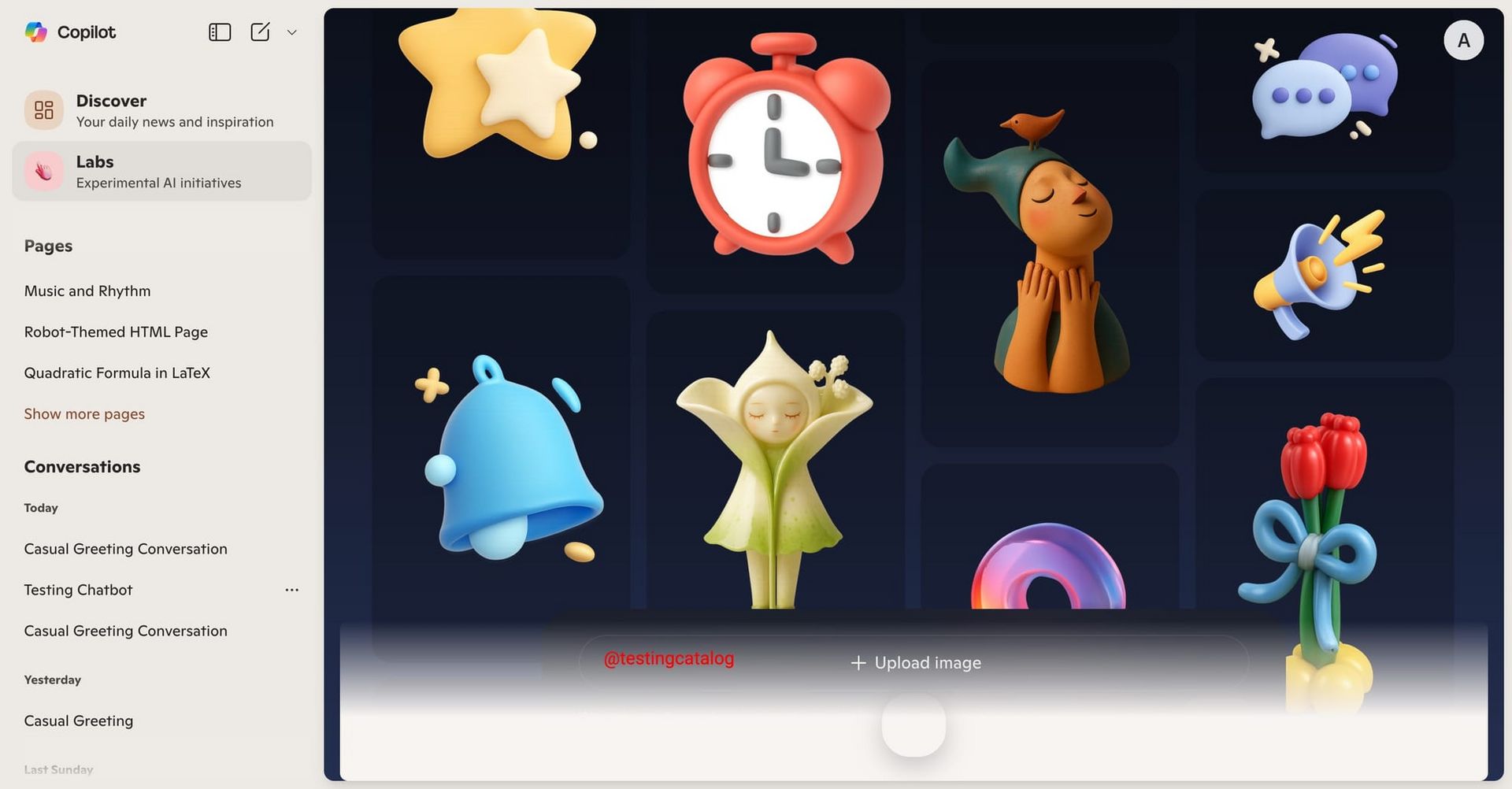
Microsoft a lansat Copilot 3D, un model care transformă imaginile în modele 3D. Este un instrument experimental disponibil în cadrul Copilot Labs, care permite conversia rapidă a unei imagini 2D (JPG/PNG, sub 10 MB) într-un model 3D exportabil în format GLB, pregătit pentru utilizare în jocuri, animație, design AR/VR sau imprimare 3D, totul gratuit pentru utilizatorii cu cont Microsoft.
Funcționează cel mai bine cu imagini clare, cu fundal simplu și iluminare bună; se descurcă bine în special cu obiecte statice, ca mobilier sau fructe, dar are dificultăți cu animale sau persoane - iar anumite conținuturi (ex. cele cu persoane celebre) sunt blocate conform politicilor de utilizare.
Open-source AI Reasoning de 6 ori mai rapid
NVIDIA a lansat familia de modele open-source de reasoning, Nemotron Nano 2. Aceste modele hibride Mamba-Transformer oferă până la de 6 × mai rapidă generare în sarcini de raționament comparativ cu modele similare (ex. Qwen3-8B), fără a compromite acuratețea — obținând performanțe egale sau superioare pe benchmark-uri complexe precum matematică, cod și limbaj multilingv. Sunt capabile să proceseze secvențe de până la 128.000 de tokeni pe un singur GPU A10G, grație unei strategii avansate de pruning și distilare.
Arhitectura este ingenioasă - majoritatea straturilor de self‑attention sunt înlocuite cu straturi Mamba‑2, iar doar aproximativ 8 % dintre straturi utilizează atenție tradițională, oferind un compromis eficient între viteză și raționament profund. Mai mult, dezvoltatorii pot activa sau dezactiva explicit raționamentul în timpul inferenței (folosind comenzi precum /think sau /no_think) și pot controla „bugetul de raționament”- adică numărul maxim de tokeni dedicați procesului intern de gândire
Poate Claude Opus 4.1 depăși OpenAI o3 și Gemini 2.5 Pro?

Anthropic lansează Claude Opus 4.1, cu îmbunătățiri la task-uri agentice, programare și raționament. Modelul este o evoluție directă a Opus 4, dar oferă performanțe superioare în sarcini de inginerie software, căutare agentică și analiză complexă a datelor. În benchmark-ul SWE-bench Verified, Opus 4.1 atinge un scor de 74,5 %, depășind versiunea precedentă (72,5 %) și modele concurente precum OpenAI o3 sau Gemini 2.5 Pro.
Modelul excelează în refactorizarea codului pe mai multe fișiere, evitând introducerea de erori și păstrând stilul original - după cum au mărturisit echipele Rakuten și Windsurf, care au observat o creștere semnificativă a eficienței în debugging, comparabilă cu saltul de la Sonnet 3.7 la Sonnet 4.
Mic, dar puternic
Google a lansat Gemma 3 270M, un model cu 270 milioane de parametrii, creat pentru fine-tuningul mai multor SLMs. Fac parte din familia Gemma 3, Gemma 3 270M este un model compact, bine optimizat pentru ajustări rapide pe task-uri specifice precum clasificare, extragere de entități sau generare de text instrucțiuni. Datorită dimensiunii reduse, oferă un raport remarcabil între acuratețe, viteză și cost, făcându-l ideal pentru rulare locală pe hardware modest, chiar offline pe dispozitive mobile sau servere eficiente. Google a publicat greutățile modelului deschis și oferă documentație completă pentru fine-tuning - inclusiv metode eficiente precum LoRA sau QLoRA - disponibile prin platforme precum Hugging Face, Keras, JAX sau Vertex AI, facilitând prototipe rapidă și scalarea în producție.
O nouă frontieră pentru modelele AI globale

DeepMind lansează Genie 3, un model care generează lumi interactive în timp real dintr-un simplu prompt text. Genie 3 este un „world model” revoluționar capabil să transforme descrieri textuale (sau imagini) în medii 3D explorabile în timp real, la rezoluție 720p și 24 fps, oferind utilizatorilor o experiență interactivă fluentă.
Spre deosebire de versiunile anterioare (Genie 1 și 2), Genie 3 menține consistența mediilor pentru câteva minute - suficient pentru a reveni într-un spațiu generat și a regăsi obiectele sau modificările exact unde le-ai lăsat. De asemenea, permite schimbări dinamice ale scenei - de la vreme, până la adăugarea de personaje - prin simple comenzi text, toate fără a fi nevoie de reîncărcare.
Ce funcționalități au fost introduse în Claude?
Anthropic a lansat Claude for Chrome, o extensie prin care poți lăsa AI-ul să îți controleze browserul. Această integrare AI funcționează ca o extensie experimentală pentru Google Chrome, accesibilă momentan doar unui număr restrâns de 1.000 de utilizatori abonați la planul Max. Claude apare într-un panou lateral în browser și are capacitatea de a citi conținutul paginilor, completa formulare, face click pe butoane și executa acțiuni la cerere, păstrând contextul navigării.
Claude Sonnet 4 suportă un context de 1 milion de tokeni. Noua fereastră de context, disponibilă în versiunea beta pe API-ul Anthropic, oferă o capacitate de lucru de cinci ori mai mare decât înainte, permițând analizarea unor coduri sursă extinse (peste 75.000 de linii) sau a multor documente în cadrul unei singure cereri
De asemenea, acum Claude îți oferă posibilitatea să înveți în timp ce scrii cod. Astfel, în cadrul Claude Code au fost introduse două moduri de învățare: Explanatory, care explică deciziile pe care le ia modelul în timpul generării codului — asemănător unui coleg senior care vorbește gândurile - și Learning, în care Claude lasă intenționat anumite secțiuni de cod necompletate și îți oferă ție șansa să le finalizezi, oferind apoi feedback asupra contribuției tale
Care sunt funcțiile noului Pixel 10? Meet the new status pro

Noul Pixel 10 vine echipat cu Gemini Nano, un model compact ce rulează direct pe dispozitiv, alimentat de cipul Tensor G5, pentru performanțe AI rapide și fără dependență de cloud.
Magic Cue este un asistent inteligent care apare contextual în aplicații precum Messages sau Phone App și îți oferă rapid informațiile de care ai nevoie - de exemplu detalii din e-mailuri, calendar sau hartă - exact atunci când ai nevoie de ele. Toate acestea se întâmplă pe device, asigurându-ți confidențialitatea.
Camera Coach este un ghid AI în timp real în camera foto, sugerând compoziții mai bune, ajustări de cadru, lumină și setări pentru a îmbunătăți calitatea fotografiilor. Funcționează prin scanarea scenei și oferirea instrucțiunilor vizuale - util atunci când vrei să faci o fotografie reușită fără prea mult efort.
Poate un AI model să se învețe să “vadă” singur?
Meta a creat DINOv3, un Computer Vision model antrenat cu Self-Supervised Learning. Noul model este antrenat pe peste un miliard de imagini fără etichete și folosește arhitecturi Vision Transformer la scară mare pentru a obține reprezentări vizuale generale. DINOv3 aduce îmbunătățiri semnificative față de DINOv2, inclusiv o tehnică numită Gram Anchoring care stabilizează învățarea pe termen lung și menține calitatea în sarcini precum segmentarea sau detecția obiectelor. În teste, modelul a atins performanțe de top pe benchmark-uri standard de clasificare și segmentare.
Noile modele de la OpenAI

OpenAI, împreună cu Retro Bio, au dezvoltat GPT-4b, un model AI specializat în descoperirea de proteine și ingineria celulară. Bazat pe o variantă compactă a GPT-4o, modelul a fost antrenat pe secvențe proteice, texte biologice și date structurale, pentru a genera variante îmbunătățite ale factorilor Yamanaka - proteine esențiale în reprogramarea celulară. În experimente de laborator, variantele GPT-4b micro au obținut o creștere de peste 50 de ori a expresiei markerilor pluripotenți comparativ cu proteinele originale, iar celulele reprogramate au demonstrat o capacitate îmbunătățită de reparare a ADN-ului și stabilitate genomică.
OpenAI prezintă gpt-oss-120b și 20b, modele open-weight cu progrese în raționament și siguranță. Modelul gpt-oss-120b, cu 117 miliarde de parametri (~5,1 B activi per token), oferă performanțe comparabile cu o4-mini la benchmark-uri de raționament, sănătate și matematică, totul rulând eficient pe un GPU de 80 GB. Varianta mică, gpt‑oss‑20b (21 miliarde parametri, 3,6 B activi), e optimizată pentru hardware de consum — poate rula pe dispozitive cu doar 16 GB RAM și, totuși, atinge rezultate peste o3‑mini în diverse teste.
De asemenea, OpenAI a lansat oficial Realtime API, cu modelul gpt-realtime speech-to-speech și noi unelte pentru dezvoltatori. Noul model, numit gpt‑realtime, este cel mai avansat model speech‑to‑speech al OpenAI. Spre deosebire de pipeline‑urile tradiționale care concatenau mai multe modele (speech‑to‑text, LLM, text‑to‑speech), acesta procesează și generează audio direct într‑un singur flux, reducând semnificativ latența și păstrând nuanțele naturale ale vorbirii. În benchmark‑uri relevante, gpt‑realtime obține o acuratețe de 82,8 % în raționament pe Big Bench Audio (față de 65,6 % în decembrie 2024), 30,5 % în urma comenzilor complexe pe MultiChallenge Audio (față de 20,6 %), și 66,5 % în apeluri funcționale (ComplexFuncBench versus 49,7 %).